
Solving Agent Tool Sprawl with DSPy: Building a Shopify Scout like System
Stop letting LLMs improvise across your tools. Use DSPy based orchestration for control, evals and optimization.

This is part 5 in a series of posts about differentiable programming for dynamic workflows using DSPy. The code is available here.
Two months ago, Tobi Lütke tweeted about Scout, Shopify’s internal research tool:
“Scout has indexed hundreds of millions of merchant feedback items from Social posts, video feedback, and all our customer support channels. Then it makes it available (via MCP) in our internal librechat tool for deep research. I use it all the time.“
The interesting question isn’t what Scout does — aggregating data sources is table stakes after all. It is how well does it route queries intelligently across those sources?
Because here’s what happens when you don’t solve routing: your LLM sees 15 tools, picks the wrong ones, and your only debugging mechanism is rewriting prompts and hoping vibes carry you through.
I’m calling this the Agent Tool Sprawl Problem, and it’s why most multi-tool agents feel unreliable in production.
In this post, we’ll see how to solve this via DSPy, and build a toy version of Shopify’s scout via DSPy orchestration.
The Tool Sprawl Problem
Here’s the architecture most teams build first.
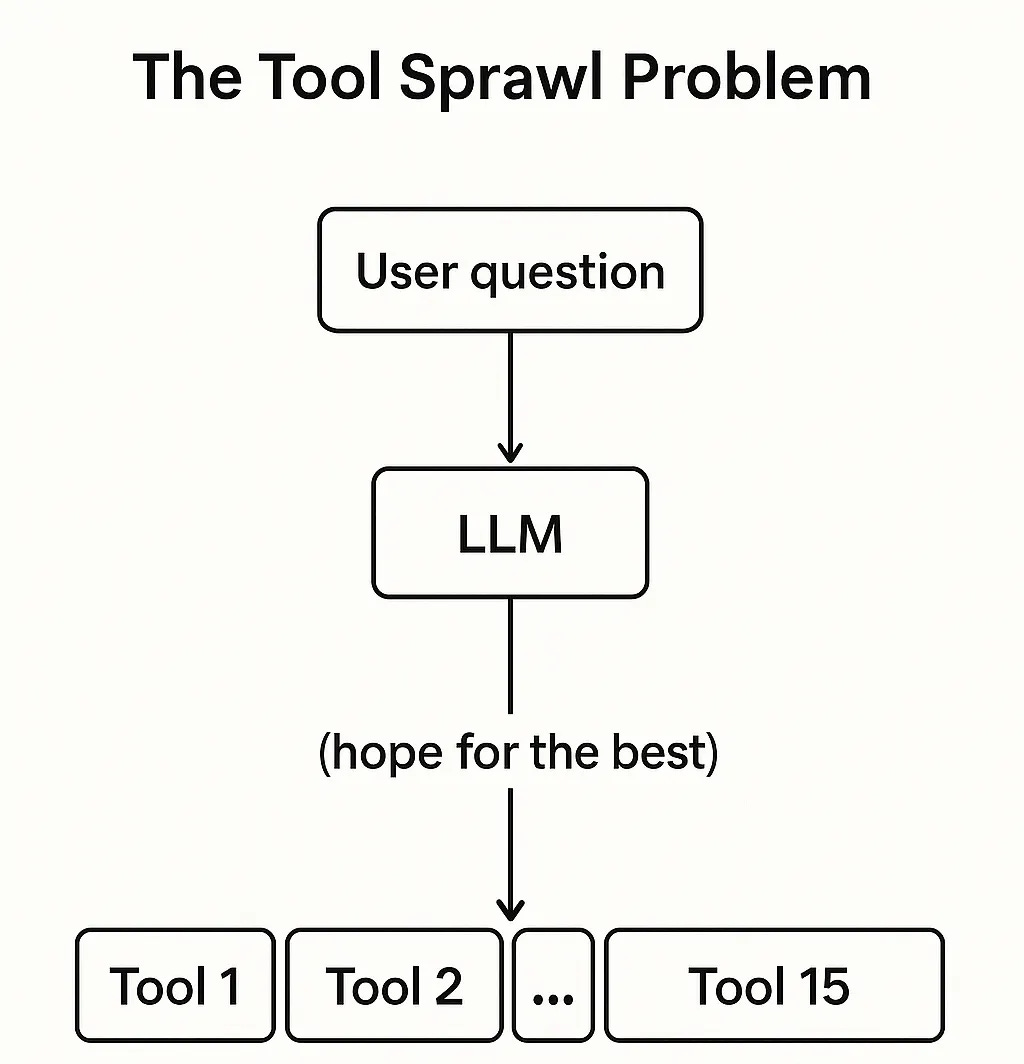
You expose all your tools via MCP. The base model sees everything. When a question comes in, it picks which tools to call. But you have no control layer. When it picks wrong, you add examples to the prompt. Then more examples. Then ALL CAPS WARNINGS. The model keeps improvising because the fundamental issue isn’t the prompt — it’s that you’ve delegated architectural decisions to a general-purpose model that doesn’t know your system.
The model can’t learn from mistakes.
You can’t see why it chose Tool X over Tool Y.
You can’t A/B test routing strategies.
You’re basically debugging by vibes.
The Fix: Orchestration Layer + Intent-Based Routing
Here’s what changes when you add a control layer.
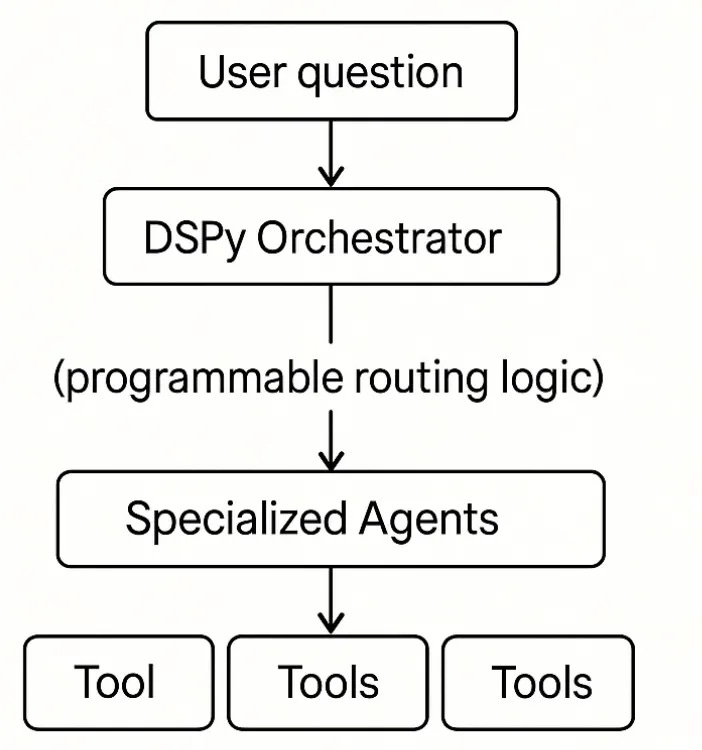
The tools don’t change. But now there’s an orchestration layer that decides which tools to call, in what order, and how to combine results. This layer is:
Observable – You can see every routing decision
Programmable – You can modify the logic in code
Optimizable – You can improve it with data (Part 2)
Let me show you how to build this, starting simple and adding sophistication.
Step 1: Intent-Based Routing
Let’s try an experiment. Instead of organizing by domain (Engineering vs Analytics), organize by operation type. Every query against your data sources falls into one of three intents:
search – Find relevant items using keywords (”find P0 tickets”)
retrieve – Get specific items by ID (”get details for SHOP-2847”)
analyze – Examine metrics and trends (”how are conversions trending?”)
This is more powerful than domain-based routing because the same question might require multiple intents. “Find P0 tickets and get details“ requires both search and retrieve.
Here’s how we define these agents.
class SearchQuery(dspy.Signature):
“”“Search for relevant information in Jira tickets and Confluence docs.”“”
question: str = dspy.InputField()
context: str = dspy.InputField(desc=”Results from previous steps (if any)”)
answer: str = dspy.OutputField(desc=”Summary of search results”)
class SearchAgent(dspy.Module):
“”“Specialized agent for searching (finding information).”“”
def __init__(self):
super().__init__()
self.react = dspy.ReAct(
signature=SearchQuery,
tools=[search_jira, search_confluence],
max_iters=4
)
def forward(self, question: str, context: str = “”):
result = self.react(question=question, context=context or “No previous context”)
return dspy.Prediction(answer=result.answer)
Notice two things:
ReAct pattern – The agent can reason and call tools iteratively. It’s not just “call this tool then that tool.” It can decide which tools to call based on what it learns.
Context parameter – This is crucial for multi-step queries. The agent receives results from previous steps, so it can build on prior work.
The other two agents follow the same pattern.
class RetrieveQuery(dspy.Signature):
“”“Retrieve detailed information for specific tickets or documents.”“”
question: str = dspy.InputField()
context: str = dspy.InputField(desc=”Results from previous steps (if any)”)
answer: str = dspy.OutputField(desc=”Detailed information from retrieved items”)
class RetrieveAgent(dspy.Module):
“”“Specialized agent for retrieving (getting specific items by ID).”“”
def __init__(self):
super().__init__()
self.react = dspy.ReAct(
signature=RetrieveQuery,
tools=[get_ticket_details, get_confluence_doc],
max_iters=3
)
def forward(self, question: str, context: str = “”):
result = self.react(question=question, context=context or “No previous context”)
return dspy.Prediction(answer=result.answer)
class AnalyzeQuery(dspy.Signature):
“”“Analyze metrics, trends, and data patterns.”“”
question: str = dspy.InputField()
context: str = dspy.InputField(desc=”Results from previous steps (if any)”)
answer: str = dspy.OutputField(desc=”Analysis with trends and insights”)
class AnalyzeAgent(dspy.Module):
“”“Specialized agent for analyzing (metrics and trends).”“”
def __init__(self):
super().__init__()
self.react = dspy.ReAct(
signature=AnalyzeQuery,
tools=[get_metric, compare_metrics, list_available_metrics],
max_iters=4
)
def forward(self, question: str, context: str = “”):
result = self.react(question=question, context=context or “No previous context”)
return dspy.Prediction(answer=result.answer)
Each agent is self-contained. They don’t know about each other. They just know how to execute their intent. This modularity is what makes the system optimizable — you can eval and improve each agent independently.
Step 2: The Orchestrator
Now we need something that generates execution plans. The orchestrator takes a question, figures out what intents are needed, and routes each step to the right agent.
class ScoutOrchestrator(dspy.Module):
def __init__(self):
super().__init__()
self.planner = dspy.ChainOfThought(QueryPlanning)
# Intent-based agent registry
self.agents = {
“search”: SearchAgent(),
“retrieve”: RetrieveAgent(),
“analyze”: AnalyzeAgent(),
}
# Intent descriptions for planner
self.intent_descriptions = “”“
Available intents:
- search: Use when you need to FIND tickets or docs using keywords (e.g., “find Safari issues”, “search for checkout docs”)
- retrieve: Use when you have specific IDs and need DETAILS (e.g., “get ticket SHOP-2847”, “get doc checkout-rewrite”)
- analyze: Use when you need to examine METRICS or TRENDS (e.g., “how are conversions trending?”, “compare mobile vs desktop”)
Examples:
- “What tickets are about Safari?” → search
- “Get details for SHOP-2847” → retrieve
- “Are mobile conversions down?” → analyze
- “Find checkout issues and check if conversions dropped” → search (find issues), analyze (check metrics)
“”“.strip()
The planning signature is straightforward.
class QueryPlanning(dspy.Signature):
“”“Decompose a user question into an execution plan.
Intent types:
- search: Find relevant tickets or docs using keywords
- retrieve: Get specific items by ID (ticket numbers, doc keys)
- analyze: Analyze metrics, trends, or compare data
“”“
question: str = dspy.InputField()
available_intents: str = dspy.InputField()
plan: List[dict] = dspy.OutputField(
desc=”List of dicts with keys: subquery (str), intent (str: search/retrieve/analyze)”
)The magic happens in execution. The orchestrator doesn’t just route — it builds accumulated context so each step can see what previous steps discovered.
# Execute each step by routing to intent-specific agent
step_results = []
accumulated_context = “”
for i, step in enumerate(steps):
agent = self.agents[step.intent]
result = agent(question=step.subquery, context=accumulated_context)
step_results.append({
“step_id”: i,
“step”: step,
“answer”: result.answer
})
# Build context for next step
accumulated_context += f”\\nStep {i} ({step.intent}): {result.answer}\\n”This context threading is subtle but critical. Consider the query: “Find P0 tickets and get details for the most critical one.”
Step 0 (search): Finds “SHOP-2847: Safari checkout crashes (Priority: P0)”
Step 1 (retrieve): Receives Step 0’s results as context, sees SHOP-2847 was found, retrieves its full details
Without context passing, Step 1 would fail — it wouldn’t know which ticket to retrieve. With context passing, the agents compose naturally.
Step 3: Tools Do the Work
Each agent has access to tools matched to its intent. The search agent can search Jira and Confluence for instance.
def search_jira(query: str) -> str:
“”“Search Jira tickets by keyword.”“”
query_lower = query.lower()
results = []
for ticket_id, ticket in JIRA_TICKETS.items():
if (query_lower in ticket[”title”].lower() or
query_lower in ticket[”description”].lower() or
query_lower in ticket[”priority”].lower() or
query_lower in ticket[”status”].lower() or
query_lower in ticket[”assignee”].lower()):
results.append(
f”{ticket_id}: {ticket[’title’]} “
f”(Status: {ticket[’status’]}, Priority: {ticket[’priority’]}, “
f”Assignee: {ticket[’assignee’]})”
)
if not results:
return f”No Jira tickets found matching ‘{query}’”
return f”Found {len(results)} ticket(s):\\n” + “\\n”.join(results)
The retrieve agent can get specific documents:
def get_ticket_details(ticket_id: str) -> str:
“”“Get full details for a specific Jira ticket.”“”
ticket = JIRA_TICKETS.get(ticket_id.upper())
if not ticket:
return f”Ticket {ticket_id} not found”
return f”“”Ticket {ticket_id}: {ticket[’title’]}
Status: {ticket[’status’]}
Assignee: {ticket[’assignee’]}
Priority: {ticket[’priority’]}
Created: {ticket[’created’]}
Updated: {ticket[’updated’]}
Description:
{ticket[’description’]}”“”The analyze agent can query metrics:
def get_metric(metric_name: str) -> str:
“”“Get current value and trend for a specific metric.”“”
metric = ANALYTICS_DATA.get(metric_name)
if not metric:
available = ‘, ‘.join(ANALYTICS_DATA.keys())
return f”Metric ‘{metric_name}’ not found. Available: {available}”
return f”“”{metric_name}:
Current: {metric[’current’]}
Previous: {metric[’previous’]}
Trend: {metric[’trend’]} ({metric[’change_pct’]:+.1f}%)
Period: {metric[’period’]}”“”In production, these would hit real APIs. The pattern is the same: agents decide which tools to call, the orchestrator decides which agents to invoke.
Example run
================================================================================
Query 1: What tickets mention Safari?
================================================================================
📋 EXECUTION PLAN:
Step 0: [search] Find tickets that mention Safari
💬 ANSWER:
The following ticket mentions Safari:
- **SHOP-2847**: Safari checkout crashes on iOS 17 (Status: In Review, Priority: P0, Assignee: Alice Chen)
================================================================================
Query 2: Get details for ticket SHOP-2847
================================================================================
📋 EXECUTION PLAN:
Step 0: [retrieve] Get details for ticket SHOP-2847
💬 ANSWER:
Ticket SHOP-2847: Safari checkout crashes on iOS 17
- **Status**: In Review
- **Assignee**: Alice Chen
- **Priority**: P0
- **Created**: 2025-01-15
- **Updated**: 2025-01-18
**Description**:
Users on Safari 17/iOS report checkout crashes at the payment step. A hotfix was deployed yesterday, and the team is currently monitoring for recovery.
================================================================================
Query 3: How are mobile conversions trending?
================================================================================
📋 EXECUTION PLAN:
Step 0: [analyze] Analyze the trend of mobile conversions over time.
💬 ANSWER:
The trend of mobile conversions over time shows a decline, with a week-over-week decrease of 8.6%. The current value is 3.2, down from 3.5 in the previous period. This suggests a negative trend in mobile conversions, which may require further investigation to identify potential causes and address them.
================================================================================
Query 4: Find P0 tickets and get details for the most critical one
================================================================================
📋 EXECUTION PLAN:
Step 0: [search] Find all P0 tickets
Step 1: [retrieve] Get details for the most critical P0 ticket
💬 ANSWER:
**SEARCH**: Found 1 P0 ticket:
- **SHOP-2847**: Safari checkout crashes on iOS 17 (Status: In Review, Priority: P0, Assignee: Alice Chen)
**RETRIEVE**: The most critical P0 ticket is **SHOP-2847**. Here are the details:
- **Title**: Safari checkout crashes on iOS 17
- **Status**: In Review
- **Assignee**: Alice Chen
- **Priority**: P0
- **Created**: 2025-01-15
- **Updated**: 2025-01-18
- **Description**: Users on Safari 17/iOS report checkout crashes at the payment step. A hotfix was deployed yesterday, and the team is currently monitoring for recovery.
This ticket is being actively worked on, with a hotfix already deployed and under observation.
================================================================================
Query 5: Are there checkout issues and are conversion rates down?
================================================================================
📋 EXECUTION PLAN:
Step 0: [search] Find tickets or documents related to checkout issues
Step 1: [analyze] Analyze conversion rate metrics to determine if they are down
💬 ANSWER:
**SEARCH**: No Jira tickets or Confluence documents related to “checkout issues” were found.
**ANALYZE**: The conversion rate metrics are down. Specifically, “mobile_conversions” decreased by 8.6% (from 3.5 to 3.2), and “checkout_completion” decreased by 4.4% (from 82.1 to 78.5) week-over-week. These declines indicate a negative trend in conversion performance, which may warrant further investigation to identify potential causes and address the issue.
================================================================================
Query 6: Get details for SHOP-3001 and check if mobile metrics are affected
================================================================================
📋 EXECUTION PLAN:
Step 0: [retrieve] Get details for SHOP-3001
Step 1: [analyze] Check if mobile metrics are affected
💬 ANSWER:
**RETRIEVE**: Ticket ID: SHOP-3001
Title: Mobile web performance degradation
Status: In Progress
Assignee: Carol Wang
Priority: P1
Created: 2025-01-14
Updated: 2025-01-18
Description:
Mobile page load times increased 20% after new analytics integration.
**ANALYZE**: Mobile metrics have been negatively affected, as evidenced by the following trends:
1. “mobile_conversions” decreased by 8.6% week-over-week, indicating fewer successful transactions on mobile.
2. “checkout_completion” dropped by 4.4%, showing a decline in the percentage of users completing the checkout process.
3. “safari_users” fell by 3.2%, suggesting reduced engagement or retention among Safari users.
These declines align with the reported 20% increase in mobile page load times, suggesting that the new analytics integration has adversely impacted mobile performance and user behavior.
================================================================================
Query 7: Find Safari-related tickets, get details for SHOP-2847, and check Safari user metrics
================================================================================
📋 EXECUTION PLAN:
Step 0: [search] Find Safari-related tickets
Step 1: [retrieve] Get details for ticket SHOP-2847
Step 2: [analyze] Check Safari user metrics
💬 ANSWER:
**SEARCH**: The Safari-related ticket found is:
- **SHOP-2847**: Safari checkout crashes on iOS 17 (Status: In Review, Priority: P0, Assignee: Alice Chen)
**RETRIEVE**: Ticket SHOP-2847: Safari checkout crashes on iOS 17
- **Status**: In Review
- **Assignee**: Alice Chen
- **Priority**: P0
- **Created**: 2025-01-15
- **Updated**: 2025-01-18
**Description**:
Users on Safari 17/iOS report checkout crashes at the payment step. A hotfix was deployed yesterday, and the team is currently monitoring for recovery.
**ANALYZE**: The Safari user metrics indicate a decline in activity and performance, likely linked to the reported checkout crash issue on iOS 17 (SHOP-2847). Specifically:
- Safari user activity is down by 3.2% week-over-week (current: 24.3, previous: 25.1).
- Checkout completion rates have dropped by 4.4% (current: 78.5, previous: 82.1).
- Payment success rates have decreased by 1.6% (current: 96.2, previous: 97.8).
These trends suggest that the Safari checkout issue is impacting user engagement and conversion rates. Monitoring these metrics in the coming days will help determine if the recent hotfix is effective in reversing these declines.
TL;DR
Routing is code, not hope – The planner generates structured plans you can log, debug, and improve
Context flows between steps – Multi-step queries compose naturally because agents see what previous steps discovered
Intent-based modularity – Each agent specializes in one operation type, making the system easier to test and optimize
Observable decisions – Every plan is structured data showing exactly what the system decided and why
What you can now do
Log every plan and see which routing decisions work
A/B test different planning strategies
Optimize agents independently (improve search without touching analyze)
Add new intents without rewriting infrastructure
Collect production data for systematic improvement
Step 4: Front It with MCP
Once you have a working orchestrator, expose it via MCP. External clients see one clean interface!
from fastmcp import FastMCP
mcp = FastMCP(”scout”)
scout = ScoutOrchestrator()
@mcp.tool()
def scout_query(question: str) -> str:
“”“Ask Scout a question about your data sources.”“”
result = scout(question=question)
return result.answer
if __name__ == “__main__”:
mcp.run()
That’s it. Clients talk to MCP. MCP routes through your orchestrator. Your orchestrator generates plans, routes to agents, agents call tools, results flow back with full context. You can connect Cursor, Claude, LibreChat or whatever other tool you like.
Why This Matters
The agent tool sprawl problem isn’t really about tools, it’s about control. When you delegate routing to a base model, you’re outsourcing architectural decisions to a system that can’t learn from feedback.
The fix then isn’t better prompts at all! It’s an orchestration layer that makes routing decisions observable, programmable, and optimizable.
This architecture gives you:
Control – Routing is code you own, not behavior you hope for
Aggregation – Clients see one interface, you manage complexity behind it
Observability – Every routing decision is structured data you can analyze
Modularity – Ship new agents without touching infrastructure
A foundation for optimization – You’re now collecting decision data
That last point is crucial. Right now this orchestrator works zero shot.
In a future post, we’ll use DSPy’s GEPA optimization to systematically improve routing accuracy. I‘ll show you how to collect golden examples, define metrics, and let DSPy automatically tune the planner’s prompts.
The difference between a demo and production isn’t just reliability — it’s the ability to improve systematically as you learn what your users actually need. And that’s what we’ll build next. Stay tuned!
Hey instead of making the three agents where every agent have more than one tool. Have you tried a single create react agent which takes the all the tools as comma seperate list along with master signature with max_iter param. Then I hope you can see the same behaviour that how it's selecting the which tool etc. The beauty is that lets say it called a tool and it failed then every time it's adding evrything such that in the next tool call definitely it will come with correct tool call with right query that needs to pass (assume it's a sql tool) . For avoiding lack of observability we can add a parameter verbose with true in langgraph pre built create react agent where we can how its thinking, acting and observing repeat.