
Optimizing Tool Selection in LLM Workflows (Part 2): A DSPy + PyTorch Benchmark
Last time, we showed how a custom PyTorch controller could replace prompt-based routing inside agent workflows. Now we put that to the test.

All code is available on github here.
In a previous post, we explored how a lightweight neural controller — a tiny PyTorch module — could replace prompt-based routing in LLM workflows. That post struck a chord. It was on the front page of HN. Readers chimed in with sharp questions. Could this scale? Was it accurate? What about argument generation? How does it hold up against GPT in the wild?
This week, I tried to answer those questions with an eval. I took the most obvious benchmark: customer support tickets, and asked a very specific question: can a local controller match GPT’s performance in choosing the right path through a workflow?
And perhaps more importantly: when it can, why should we care?
A Question of Responsibility
There’s a pattern I see again and again in modern agentic workflows. It looks simple on the surface:
A user submits a query.
An LLM decides which tool to call.
The tool executes.
Another LLM interprets the output and produces a reply.
This chaining of LLM calls feels elegant because you hand over the entire workflow to a language model and let it orchestrate the steps. It’s fast to prototype, flexible to adapt, and easy to debug — but up to a point.
Each decision point — “Should we refund the customer?”, “Should we escalate this?” — becomes a full GPT call. And with each call comes more tokens, more cost, more context to reintroduce. You find yourself burning inference time on problems you’ve already solved.
Moreover, the LLM isn’t even learning from its past choices. It makes the same inference again and again, in a stateless and expensive manner
What We Set Out to Measure
This post is about replacing that first decision step — the tool selection — with a learned function.
We wanted to answer a narrow but important question:
Can a local controller, trained on a few thousand examples, match GPT’s ability to decide whether a customer should get a refund?
To test this, we created a dataset of 1000 support tickets, synthetically generated and labeled using GPT-4o. These tickets were phrased to mimic real-world conditions: short, noisy, sometimes vague. They asked about late deliveries, missing items, unresponsive drivers — the typical long tail of customer frustration.
We split this dataset into 800 training examples and 200 test examples (after augmentation). Then we trained a simple RNN to act as a binary classifier..
Building the Controller
The controller was deliberately minimal. A small embedding layer, a GRU, and a linear output — that’s it. No pretraining, no tricks, no fancy encoders. (Note: this could be as complex a model as we like, from simply using OpenAI embeddings to using a fully fine tuned ToolCall model).
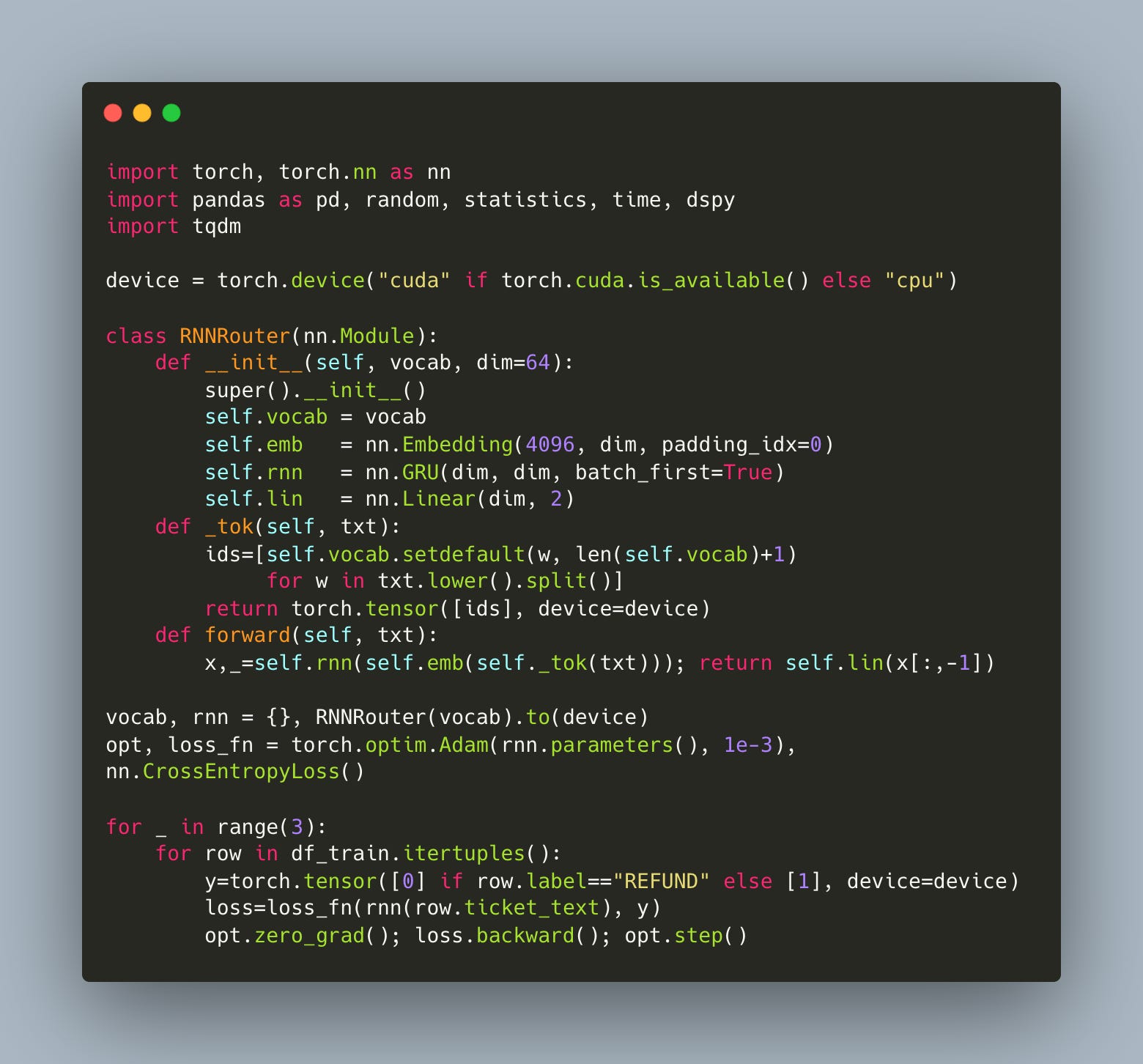
This model receives raw text, tokenized into word-level indices using a vocabulary built on-the-fly, and learns to output a softmax over two choices: REFUND or NO_REFUND.
Training took less than 10 seconds on a Google Colab T4 instance. Accuracy on the held-out set was perfect — not because the model was overfit, but because the classification task itself was simple. The head queries (late order, missing item) dominate the distribution.
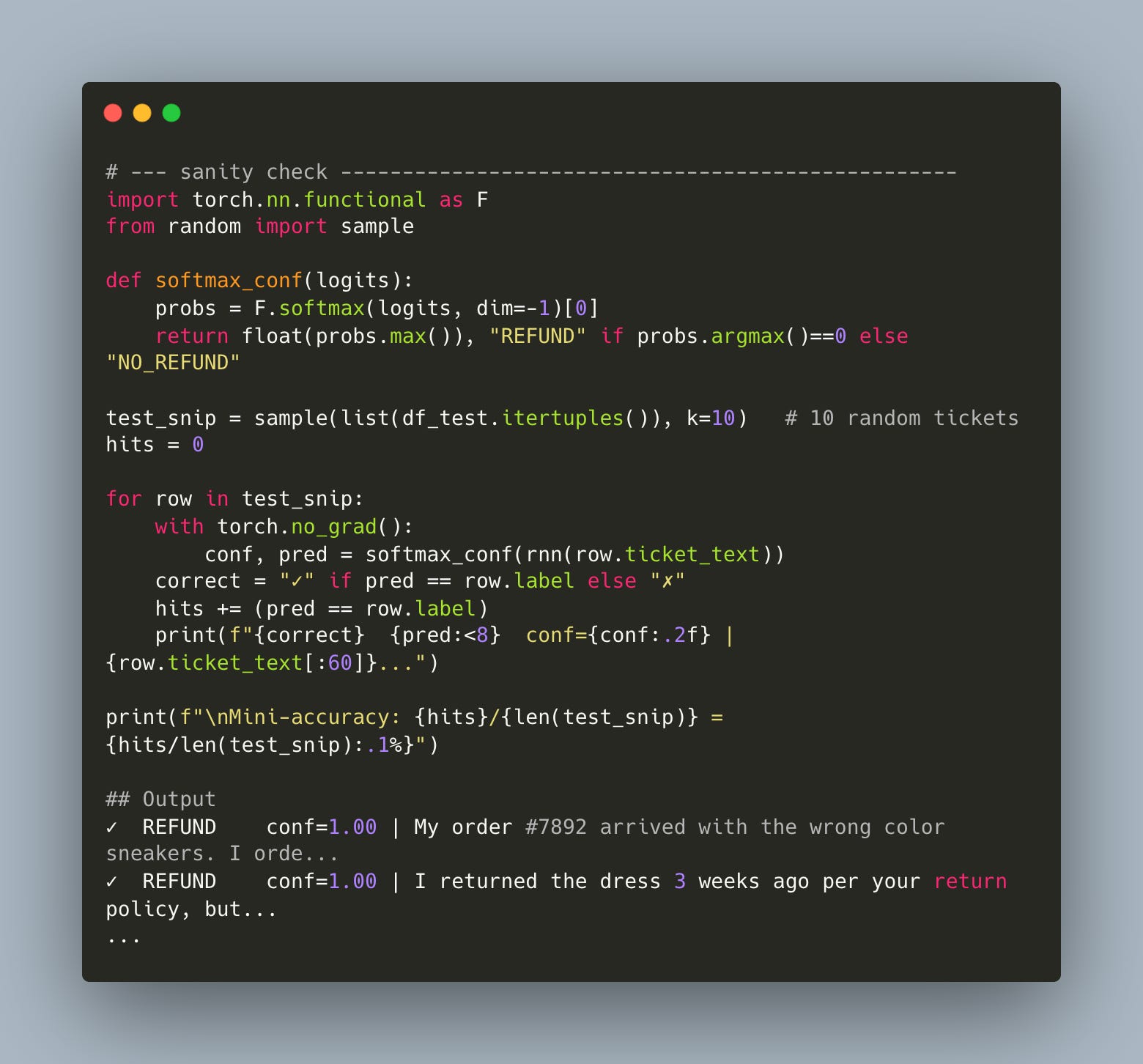
And here’s a simple sanity check.
Routing with DSPy
Next, we built two agents using DSPy, a structured framework for composing LLM modules into pipelines:
Agent A used GPT-4o for both classification and reply.
Agent B used the trained RNN for classification, and GPT-4o for the reply.
The only difference being: who decides.
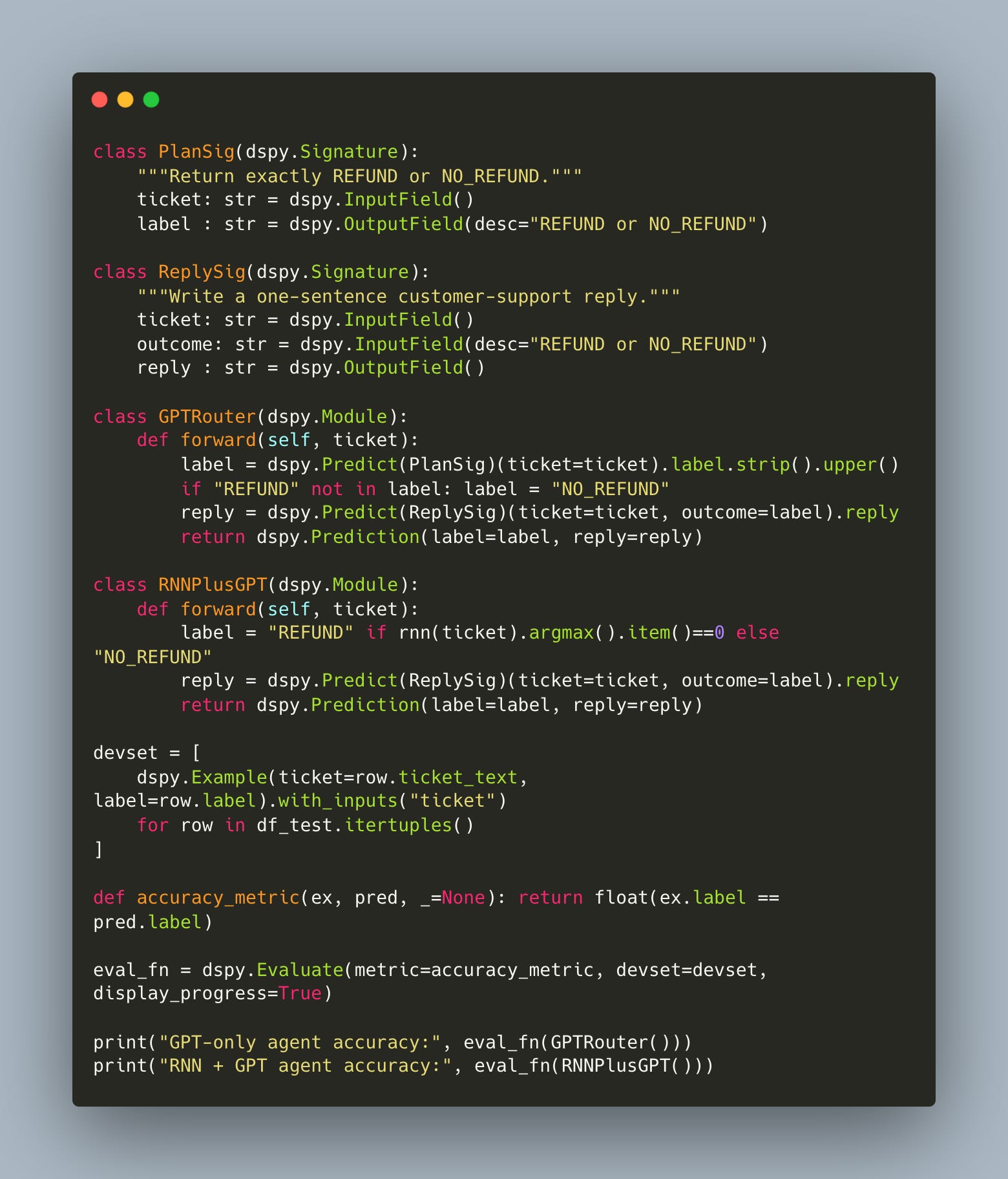
This was a clean separation of control logic from generation. The reply prompt was exactly the same in both agents. Only the routing mechanism varied.
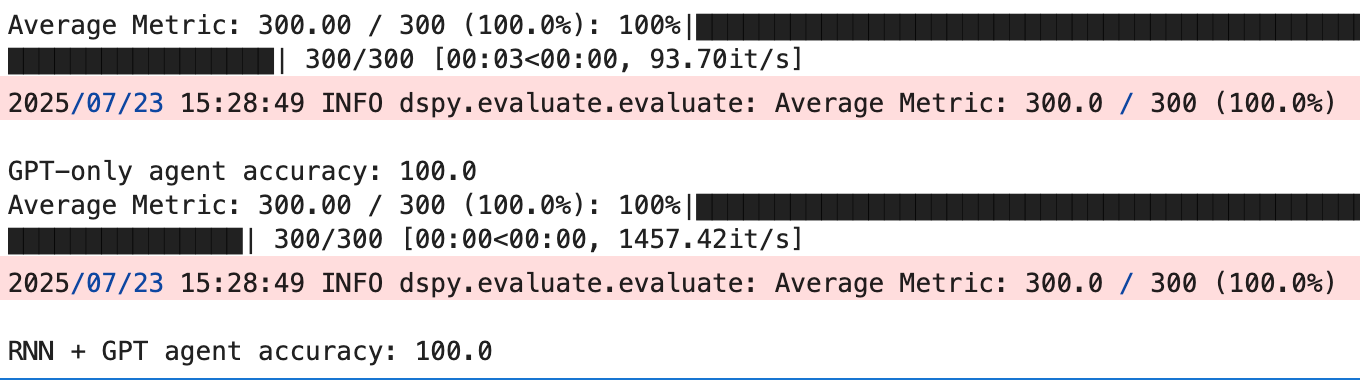
Evaluation
We evaluated both agents using DSPy’s built-in Evaluate block and captured the actual cost via dspy.LM.history, which records token usage and pricing metadata for each LLM call.
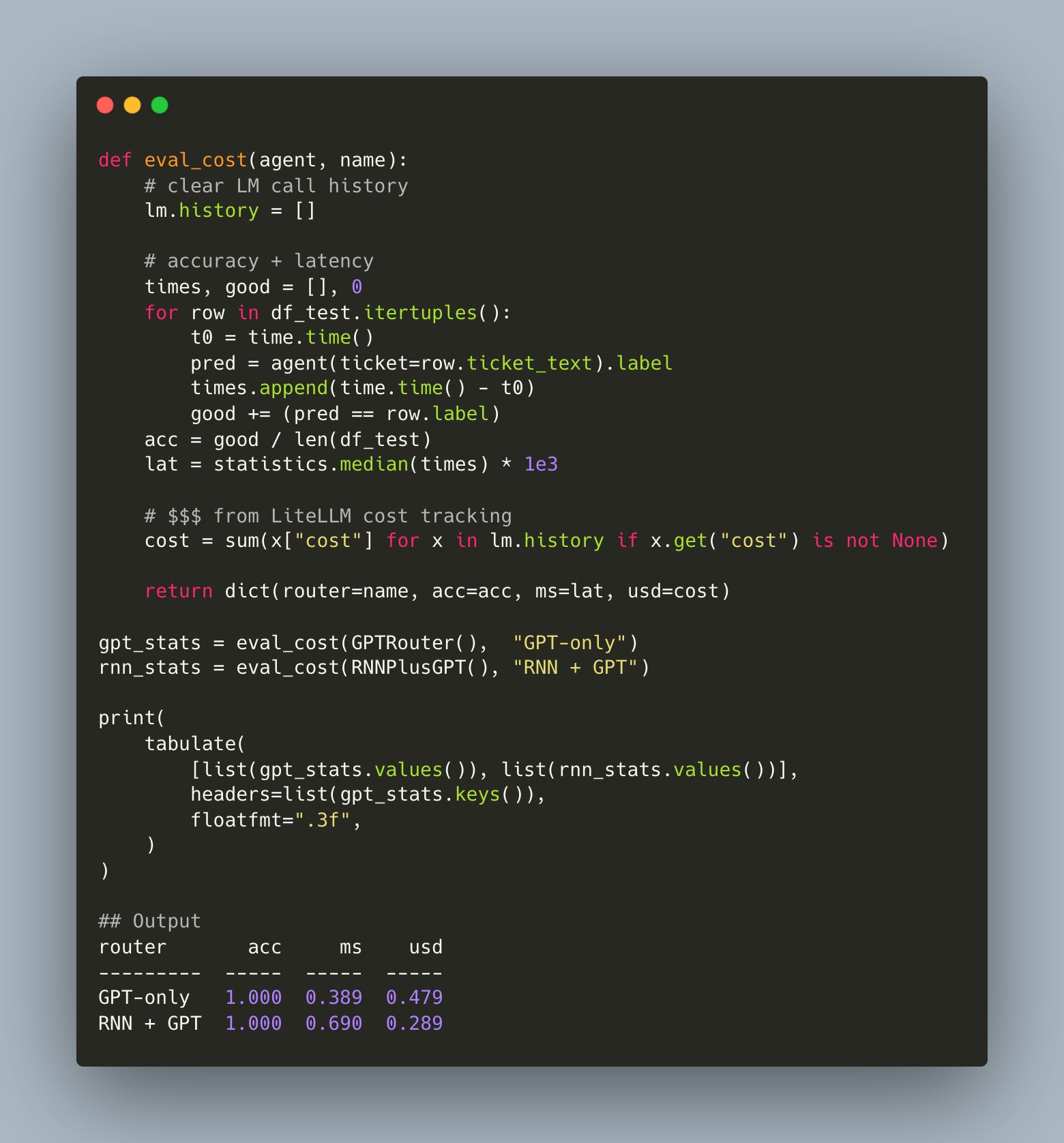
The RNN controller matched GPT in accuracy. And because it handled classification locally, it cut API usage in half. That translates to a 40% reduction in cost, with a negligible increase in end-to-end latency.
And that latency could be reduced further. The current implementation evaluates the RNN serially, without batching, and runs on CPU by default. Even with those handicaps, the controller is competitive.
What’s the Takeaway?
This experiment was deliberately simple. It was meant to do an eval of one idea:
What happens when we remove tool selection from the prompt, and treat it as a learnable layer?
The answer: nothing breaks. In fact, everything gets easier.
The system becomes more modular.
The model becomes more inspectable.
The workflow becomes cheaper to run.
More importantly, it hints at a future where control flow lives outside the LLM. Where we build agents that act more like programs — with structure, abstraction, and reusable parts.
What’s next?
The next frontier is argument learning — teaching controllers not just which tool to call, but how to call it.
If a refund is due, how much? If an escalation is needed, to whom?
In future posts, I’m going to explore the synthetic-history trick: passing in fake traces so that the LLM remains in-distribution even when routing is offloaded. And comparing this controller to small finetuned language models — the kind you might run locally in production. When I find some cheap GPUs to test on.
🔥 read. Love the content.